Pipeline Engine Requirements
Die Civitas-Plattform benötigt eine Pipeline Engine, die Daten zwischen verschiedenen Quellen und Zielen transportiert, transformiert und bereitstellt. Pipelines sind Teil von DataSets und werden innerhalb von DataPools betrieben. Die Engine muss sowohl zeitgesteuerte als auch ereignisgetriebene Verarbeitung unterstützen und dabei in einer Kubernetes-Umgebung mit eingeschränkten Rechten betrieben werden können.
Dieses Dokument beschreibt die funktionalen und nicht-funktionalen Anforderungen an die Pipeline Engine. Die Bewertung der Lösungsoptionen erfolgt in:
- options.md -- Lösungsraum (alle evaluierten Optionen)
- ruled_out.md -- Ausgeschlossene Optionen mit Begründung
- comparison.md -- Vergleich der verbleibenden Kandidaten
- sketch_redpanda_connect.md -- Architekturskizze Redpanda Connect
- sketch_nifi.md -- Architekturskizze Apache NiFi
Pipeline-Varianten
Die Engine muss folgende Ausführungsmodelle unterstützen:
- Zeitgesteuerte Ausführung: Cron-/Scheduler-basierte Jobs
- Ereignisgetriebene Verarbeitung:
- Bereitstellung von MQTT-Endpunkten bzw. MQTT-naher Verarbeitung
- WebHooks
- HTTP-Endpunkte: Synchrone Request/Response-Verarbeitung
- Batch & Stream: Sowohl Stapel- als auch Echtzeitverarbeitung
Konnektoren
- Standard-Konnektoren für MQTT, HTTP, SQL und ähnliche Systeme
- Verarbeitung von Dateien (binary/blob, text), strukturiert und unstrukturiert
Prozessoren
- Datentransformation, insbesondere JSON, aber auch allgemeine Mapping-/Validierungslogik
- Persistierung in SQL, HTTP, MQTT und weiteren Zielsystemen
- Kontrollfluss: if/then/else, switch/case, ggf. Schleifen
- Bereitstellung von Daten über APIs
- Fehlerbehandlung (Retry, Dead-Letter, etc.)
Performance
Skalierung
- Horizontale & vertikale Skalierung
- Skalierbarkeit von: Konfigurierbarkeit von Pipelines, Parallelität der Datenverarbeitung
Mengengerüst
Das erwartete Produktionsszenario (Referenz: Berlin):
| Parameter | Wert |
|---|---|
| Datensätze gesamt | bis zu 5.000 |
| DataPools | 200-300 |
| Datensätze mit Pipelines | ca. 500 (Rest ist statisch) |
| Tabellen pro Datensatz | ca. 4 |
| Zeilen pro Tabelle | ca. 250 |
| Nutzer (lesend) | bis zu 20.000 |
| Nutzer (verwaltend) | ca. 400 (ca. 2%) |
| Hochfrequente Daten (IoT) | alle 0,5-1 Sekunde |
Offene Punkte:
- Anteil dynamischer Datensätze mit Sensorik in der Stadtverwaltung -- noch zu erfragen
- Frequenz und Volumen von IoT-Use-Cases -- noch zu erfragen
Ressourceneffizienz
- Effiziente/flexible Nutzung von Ressourcen
- Ungenutzte Sandboxes sollten keinen sehr hohen Ressourcenbedarf haben
Security
Isolation
Pipelines sollen technisch auf Pipeline-Ebene isoliert werden -- jede Pipeline ist eine eigene Security Domain.
- User-to-User Isolation: Nutzer dürfen nicht auf Pipelines/Daten anderer Nutzer zugreifen, für die sie keine Berechtigung haben
- User-to-Platform Isolation: Nutzer dürfen nicht auf Plattform-interne Ressourcen zugreifen
- Pipeline-to-Pipeline Isolation Technisch soll auf Pipeline Ebene isoliert werden; Pipelines sollen getrennte Security Domains sein, Pipelines eines Datasets liegen in einer gemeinsamen Domain
Berechtigungsmodell: Rolle-Permission-DataSet. Pipelines sind Teil eines DataSets.
Confidential DataSets
- DataSets (insb. Confidential) müssen für die Nutzung in anderen DataPools explizit freigegeben werden
- Wenn ein DataSet confidential ist, muss sich dieses Attribut durchziehen und überall sichtbar sein
- Zukünftiges Feature: Explizite Freigabe der Nutzung eines confidential DataSets durch dessen Owner
- Durch die Freigabe entsteht eine in anderen Datasets verwendbare Datenquelle
Übersicht incl. Beipsiel:
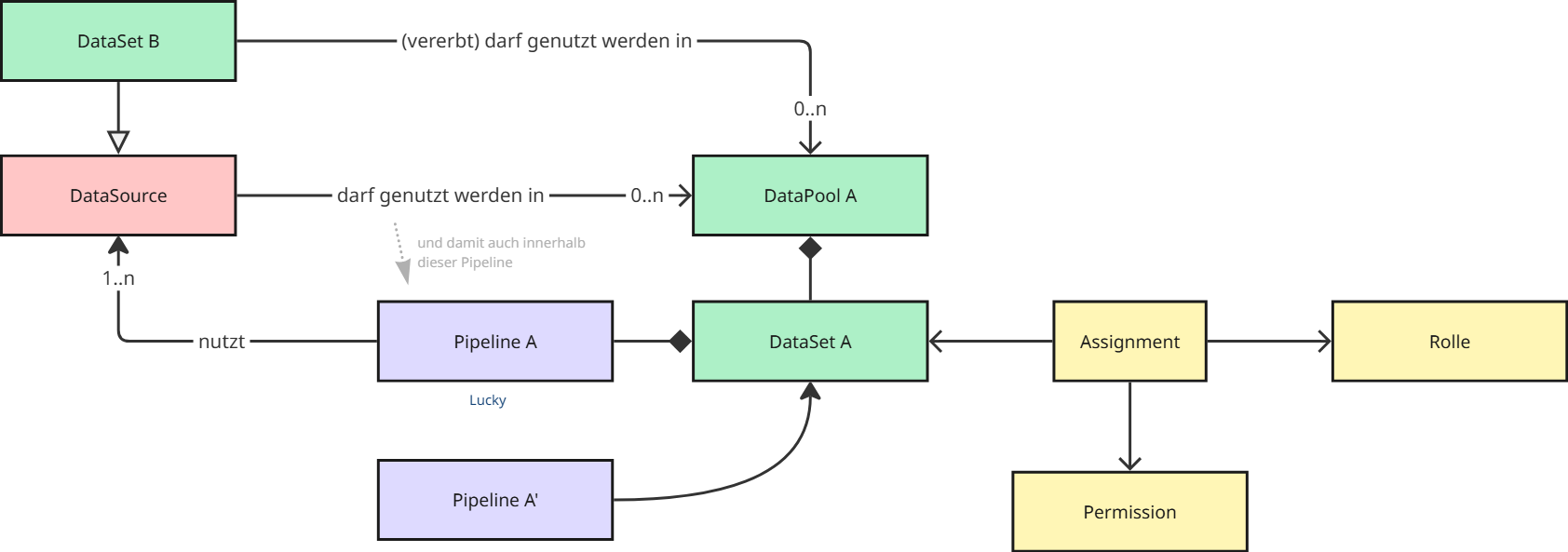
- Ein DataSet B, das von User Lucky in DataPool A "genutzt werden darf", muss trotzdem mit den gelben Entitäten noch für Lucky für READ berechtigt werden. Es braucht also das "USE" zwischen grün und grün und "READ" zwischen gelb und grün.
Threat Model
Relevante Angreifer-Klassen und deren Einstufung:
| Angreifer-Klasse | Beispiel | Einstufung |
|---|---|---|
| Externer Angreifer (unauthentifiziert) | Netzwerkzugriff auf Pipeline-Endpunkte | Muss abgewehrt werden (Ingress, NetworkPolicies, AuthN) |
| Authentifizierter Nutzer (lesend) | Zugriff auf fremde DataSets | Muss abgewehrt werden (RBAC auf Pipeline-/DataSet-Ebene) |
| Authentifizierter Nutzer (verwaltend) | Bösartiger Code in eigener Pipeline, der auf fremde Daten zugreift | Muss durch Isolation oder Einschränkung der verfügbaren Prozessoren begrenzt werden |
| Plattform-Admin | Vollzugriff | Trusted — kein Schutzziel |
| Advanced Persistent Threat (APT) | Gezielte Exploitation von JVM/Kernel-Schwachstellen | Kann zum Beipsiel durch Code Scans von Script Knoten abgeschwächt werden. Zusätzlich kann die Verwendung gefährlicher Knoten evtl. auf trusted User reduziert werden |
Die dritte Klasse (verwaltender Nutzer mit bösartiger Absicht) ist das entscheidende Differenzierungsmerkmal für die Isolationsbewertung der Pipeline Engine. Die gewählte Lösung muss dokumentieren, wie sie diesen Fall adressiert — sei es durch Prozess-Isolation, RBAC-Einschränkung gefährlicher Prozessoren, oder eine Kombination beider Maßnahmen.
Betrieb
- Kubernetes-Deployment in einem Namespace mit limitierten Rechten (keine CRDs, keine ClusterRoles)
- Deployment über Helm
- On-Prem- und Air-gapped-Betrieb muss möglich sein
- Versionierung der Pipeline-Definitionen in einer externen Registry