Persist & transform data
Role: Data Architect, Data Steward
Goal: You want to build pipelines, transform your data, and prepare it for consumption.
Required Permissions: create Dataset, release Dataset
What you will achieve
After completing this guide, you will have:
- Created a Dataset
- Defined a Pipeline
- Managed access permissions
- Set the Dataset status to mark it as ready
Before you start
- Verify that you can create Datasets. If this option is unavailable, contact your Tenant Admin to request access.
Understand your data flow
Before building a pipeline, make sure you understand how your data flows through the system. In CIVITAS/CORE, data is processed through pipelines.
This means:
- data is loaded from a Data source
- transformed step by step
- and prepared for use in a Dataset
In this guide, we demonstrate how to persist and transform data using this example use case. It shows how master data and measurement data are processed in pipelines and stored as Observations in a SensorThings API backend.
→ You will find additional context from the Smart Meter energy use case in the highlighted boxes throughout this guide.
Requirements
Two types of data are processed:
- Master data → used to create SensorThings entities such as Things and Datastreams
- Measurement data → continuous smart meter values received via MQTT
Pipelines are used to:
- load data from Data sources
- transform and map the data
- provide the data for further use
Make sure you have:
- available Data sources for master data and measurement data
→ Before measurement data can be stored, the required SensorThings entities must exist. In this guide, you will build pipelines to process both data flows.
Step-by-step guide
Step 1: Create a Dataset
- Go to Datasets
- Click Create Dataset
- Enter Name and hit Create and continue
- Add Base Information in the 1st section and hit Save
Create a Dataset to combine and process smart meter data from different Data sources.
Example name:
- Smart Meter energy usage
Step 2: Define a pipeline
- Click Load and provide data in the 2nd section Data flow
The pipeline editor is a canvas-based interface that allows you to work freely. You can add, configure, and connect nodes in any order.
- Enter a name for the pipeline at the top of the canvas
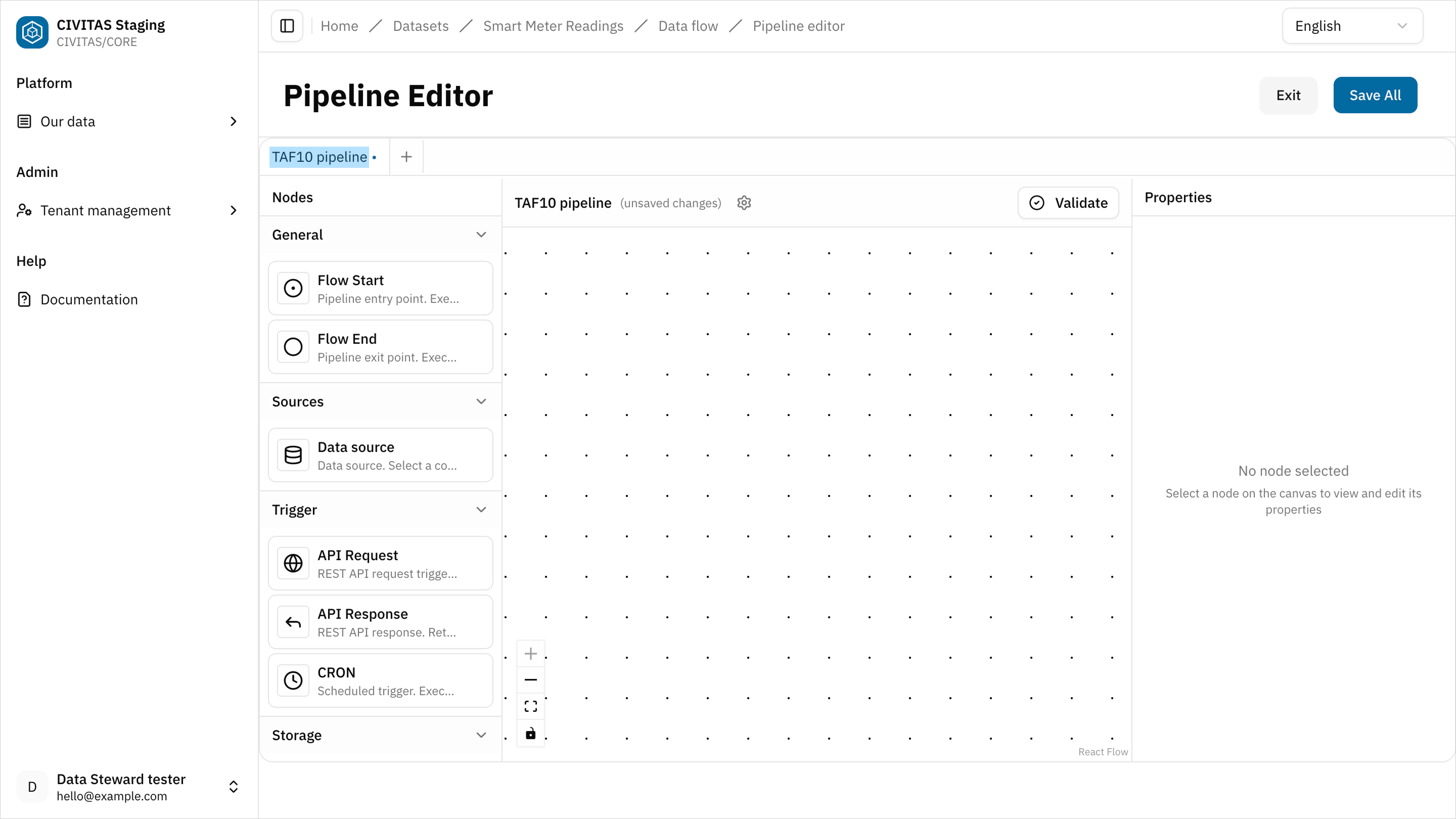
It helps you identify and manage multiple pipelines within a Dataset
- Add nodes to the canvas
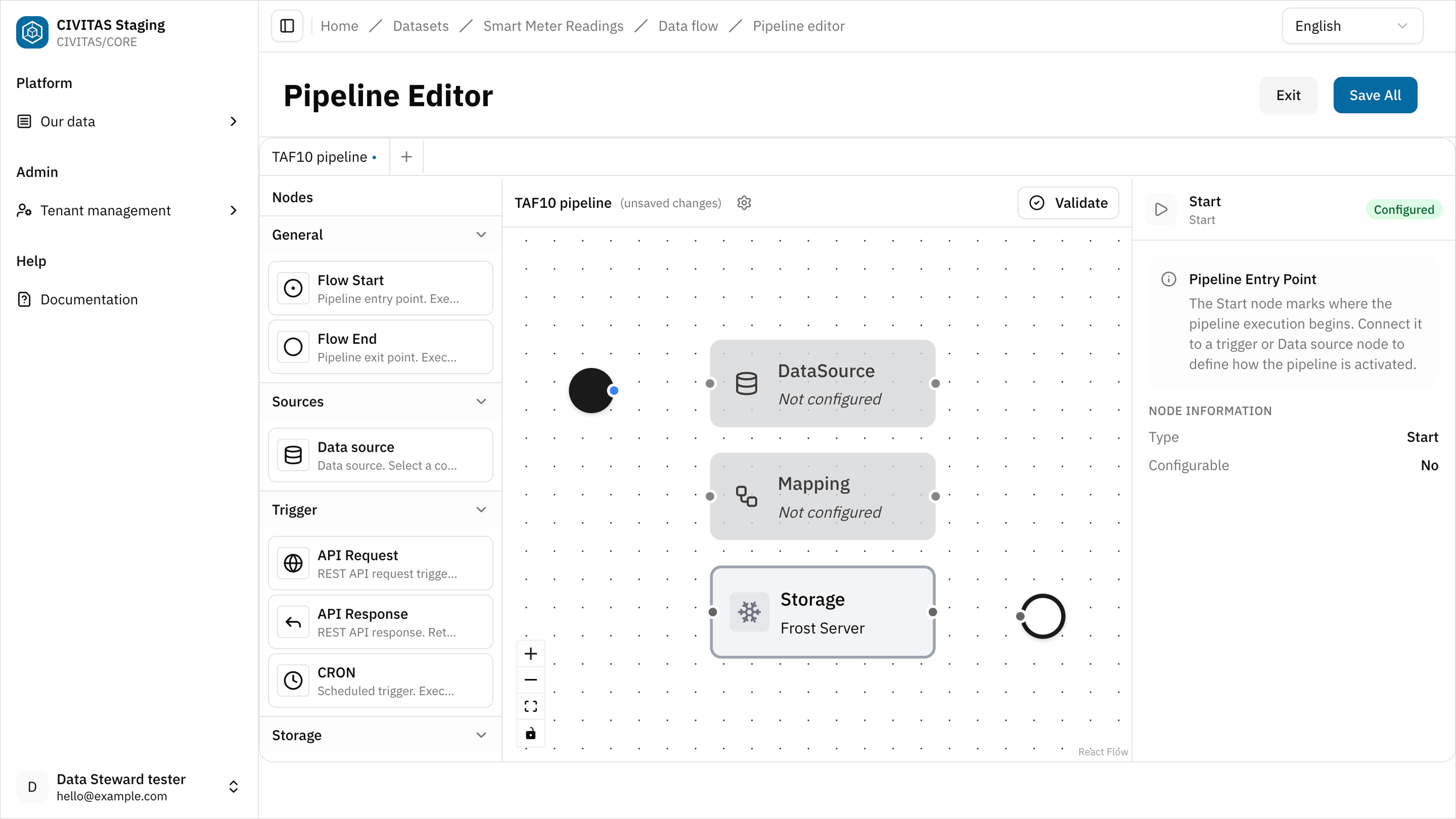
In CIVITAS/CORE, every pipeline has a defined structure:
- a Flow start → marks the beginning of the pipeline
- a Flow end → marks the end of the pipeline
Between these nodes, you can define your data flow using different nodes.
Pipelines are flexible:
- they can start with a Data source or be triggered by an event (e.g. schedule or API request)
- they can include one or more transformation nodes (e.g. Mapping)
- they can end by storing data or returning a response
What matters:
- all nodes must be correctly connected
- the pipeline must pass validation
Example pipelines:
- Load and store data: Flow start → Data source → Mapping → Storage → Flow end
- Process and return data: Flow start → API request → Storage → Mapping → API response → Flow end
- Click on a node to configure it based on your use case
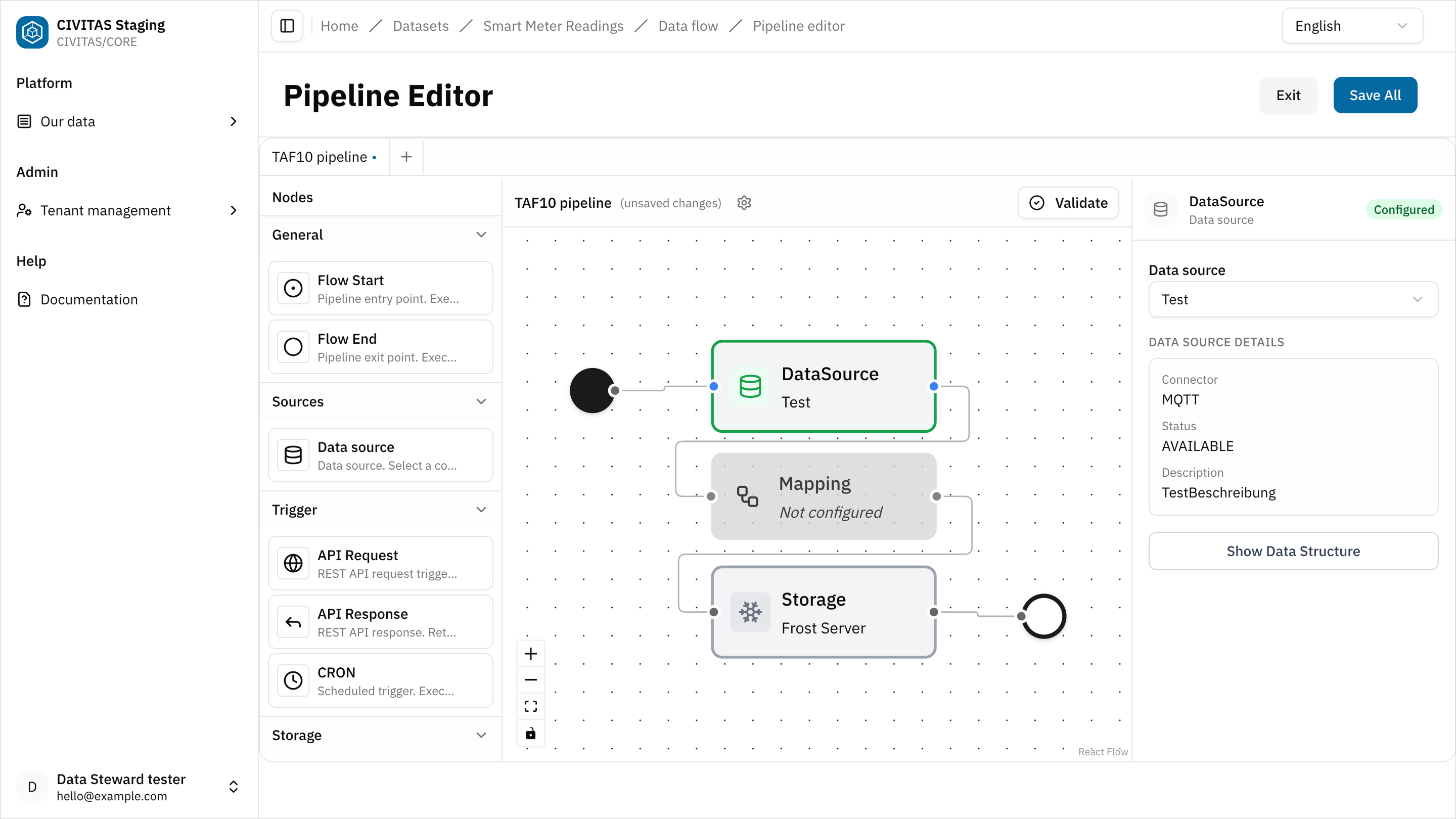
- Connect all nodes to complete the pipeline
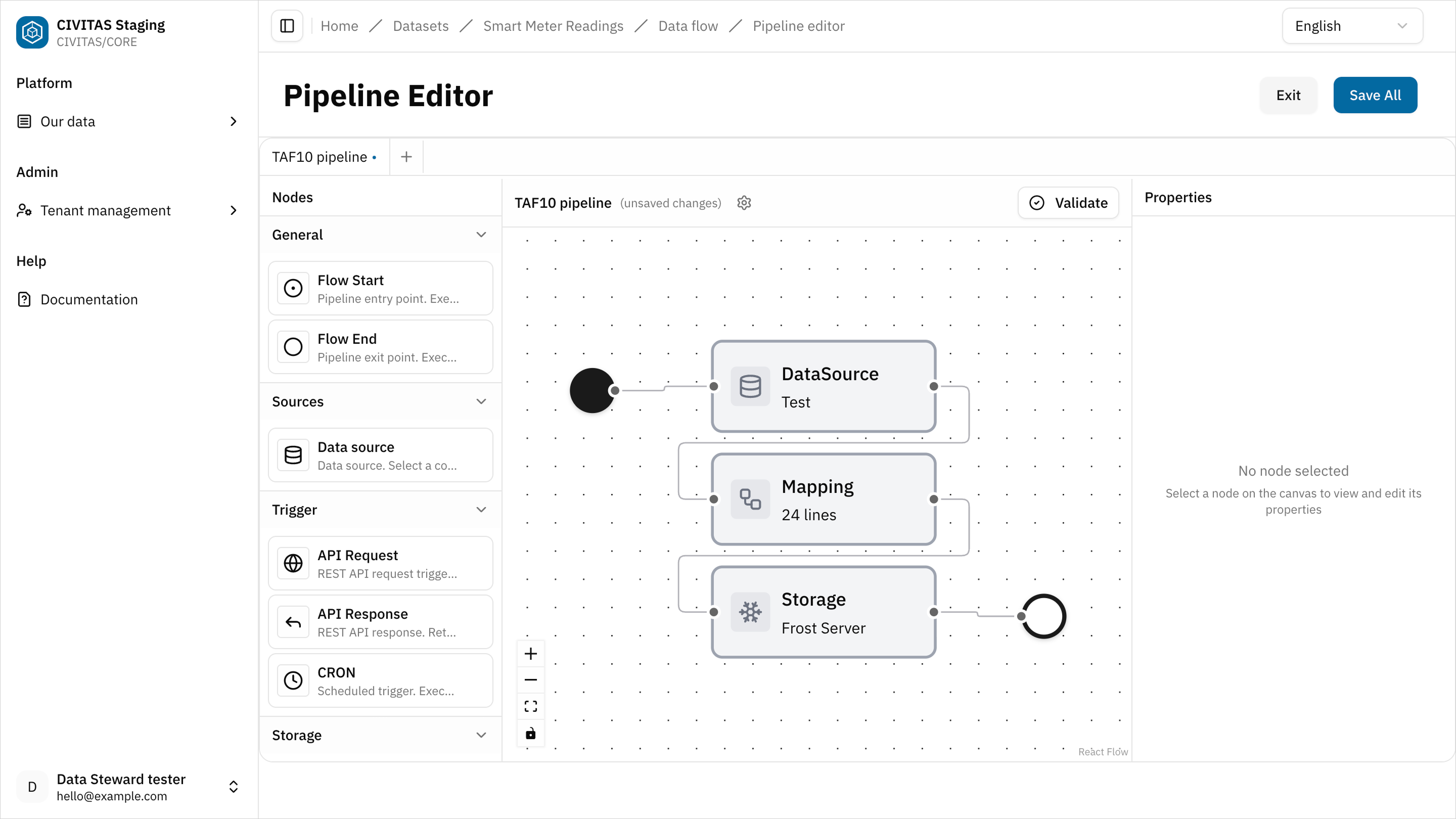
-
Click Validate to ensure that all nodes are correctly configured and connected
-
Fix any issues if needed, then hit Save and turn back to the detailview page of the Dataset
This use case requires two pipelines within the same Dataset:
- a master data pipeline
- a measurement data pipeline
Pipeline 1:
Start with the master data pipeline and follow the steps above. Use the configuration below as a reference.
Example pipeline name: Smart Meter Master Data
Pipeline structure: Flow start → CRON → Data source → Mapping → Storage → Flow end
CRON node: Defines when the pipeline runs. For example every 30 seconds:
*/30 * * * * *
Data source node: Assign the PostgreSQL Data source created earlier.
Mapping node: Transforms master data into SensorThings entities.
root = {
"things": [
{
"name" : json("device_name"),
"description" : json("device_description"),
"properties" : {
"reference" : json("device_ext_id")
},
"Locations": [
{
"name": json("device_name"),
"description": json("device_description"),
"encodingType": "application/geo+json",
"location": json("device_location").parse_json()
}
],
"Datastreams": json("definitions").parse_json()
}
]
}
Storage node Stores the transformed data in the SensorThings API backend (e.g., FROST Server).
Pipeline 2:
Now, open a new pipeline tab and define the measurement data pipeline. Follow the same steps as above and use the configuration below as a reference.
Example pipeline name: Smart Meter Measurement
Pipeline structure: Flow start → Data source → Mapping → Storage → Flow end
Data source node: Assign the MQTT Data source created earlier.
Mapping node Transforms incoming messages into Observations.
let gateway = this.gatewayId
root.observations = this.measurements.map_each(m -> m.measuredValues.map_each(mv -> {
"phenomenonTime": m.measurementTimestamp,
"result": mv.value.number().catch(mv.value),
"resultTime": m.measurementTimestamp,
"parameters": {
"reference": $gateway,
"name": mv.obisCode
}
})
).flatten()
Storage node Stores the transformed Observations in the SensorThings API backend (e.g., FROST Server).
Step 4: Open and manage access permissions
- Click Edit Groups and Roles in the 3rd section Access Management
- Add a Group
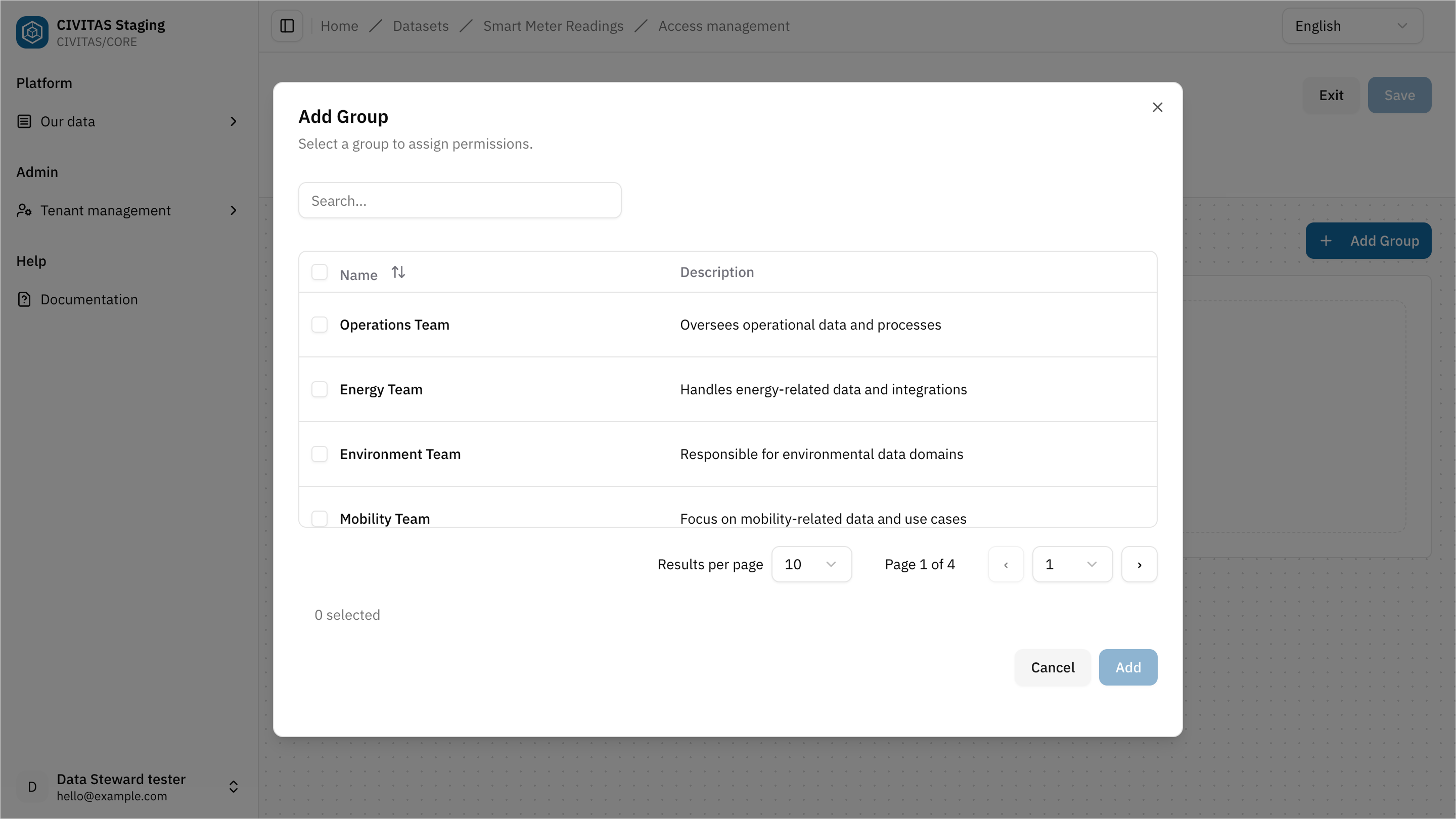
- Assign a Role to the Group
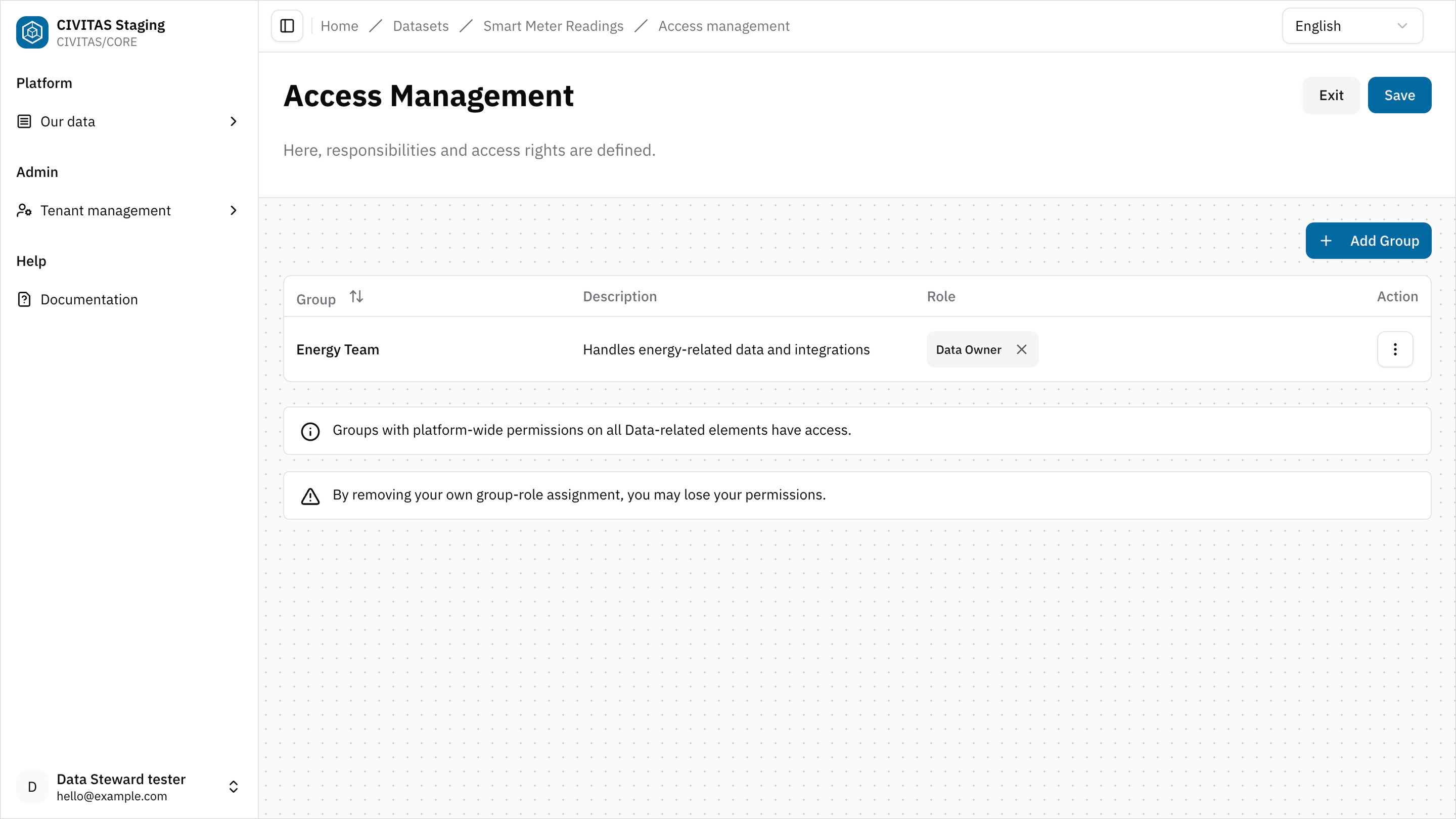
- Repeat these steps to add more Groups and Roles
- Hit Save and Turn back to the detail view of the Dataset
Step 5: Mark the Dataset as ready
→ Setting the status to Ready signals that the creation phase of the Dataset is complete. The Dataset is now prepared for review.
- Change the Status to Ready
- Contact a Data Owner or Data Gatekeeper to review and release it.
You can:
- share a direct link to the Data source
- or provide the name of the Data source
Outcome
The Dataset is Ready and can now be reviewed and released.
Summary
You have successfully:
- Created a Dataset
- Defined a Pipeline
- Configured access permissions
- Marked the Dataset as Ready
Next
You have completed the creation phase of your Dataset. In the next guide, you will:
- review a Dataset
- release it for use
- make it available to others
→ Continue with Release data